问题背景
在一个应用中会产生大量的业务数据,这些数据往往需要一个ID来标记,在关系型数据库中,主键往往就是这个作用。
在大多数数据库中,自增的64bit long类型主键,就是用来解决这个问题的。有时,我们必须在应用层控制ID的生成,
这时我们就要缓存下最近生成的ID是多少,以此来跟踪生成的序列。
如果数据库中的数据做了分片(shard,分库分表),那么在一个表中自增的64bit long主键显然不能适用,多个节点下
必然会发生碰撞问题。与此类似,当应用分布在多个节点运行的时候,简单在内存缓存最近的一个ID,也同样不能满足需要。
分布式环境下的解决方案
中心式
数据库的中心化自增
Flickr的Ticket Server方案
MySQL的自增显然不能在多库多表的情况下使用,那使用单库单表呢?
活用MySQL的REPLACE INTO。
REPLACE works exactly like INSERT, except that if an old row in the table has the same value as a new row for a PRIMARY KEY or a UNIQUE index, the old row is deleted before the new row is inserted.
新建两张表,Tickets32 for 32-bit IDs, and Tickets64 for 64-bit IDs.
1 | CREATE TABLE `Tickets64` ( |
当需要一个新的64bit唯一ID时,执行以下SQL:
1 | REPLACE INTO Tickets64 (stub) VALUES ('a'); |
因为是单库,怎么解决单点故障问题呢?把ID的数值分成奇数和偶数,在两台数据库服务器上部署。
配置如下:
1 | TicketServer1: |
Redis
若系统中已经依赖了Redis,使用Redis也是很好的选择,加上现在Redis已经有了集群化的高可用方案。
Redis的INCR命令,可以直接获取增加后的值。如果需要定制更复杂点的生成算法,使用lua脚本结合多个命令即可,lua脚本可以保证原子性。
缺点就是依赖Redis啦,每次获取都有一次远程调用,如果很担忧效率的话,可以一次获取批量的ID。
Zookeeper
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID。性能方面会不太理想,但也算一种思路。
其他的分布式集群协调器
在不使用数据库的情况下,通过一个后台服务对外提供高可用的、固定步长标识生成,则需要分布式的集群协调器进行。
一般的,主流协调器有两类:
- 以强一致性为目标的:ZooKeeper为代表
- 以最终一致性为目标的:Consul为代表
ZooKeeper的强一致性,是由Paxos协议保证的;Consul的最终一致性,是由Gossip协议保证的。
在步长累计型生成算法中,最核心的就是保持一个累计值在整个集群中的「强一致性」。同时,这也会为唯一性标识的生成带来新的形成瓶颈。
参考:https://juejin.im/entry/57fe1be1bf22ec0064ad96ce
UUID
Universally unique identifier (UUID),有时也被称为globally unique identifier(GUID)。
拥有RFC标准,应用非常广泛。
在微软的相关类库中,直接找GUID就可以了。
在Java语言中,可以直接使用java.util.UUID类的randomUUID()静态方法,直接可以得到一个类型4的UUID,
这也是最常用最简单的生成方法。
那么什么是类型4呢,是基于伪随机生成UUID的一种方法类型,具体可以学习下UUID的Wiki。
标准UUID的优势:
- 各大编程语言自带实现,编码简单,直接使用。没有其他依赖限制。
- 性能好。
- 全球唯一,碰撞率极小。
缺点:
- 没有顺序性。
- 字符串存储,一般需要36个字符表示,比较占用存储空间。
- 随机生成,可读性较低。
- 用作数据库主键或作为索引的话,查询效率会比较低。UUID与自增64bit long ID的数据库效率比较
Snowflake算法
Twitter贡献的开源分布式ID生成算法,可以生成一个64bit long型ID。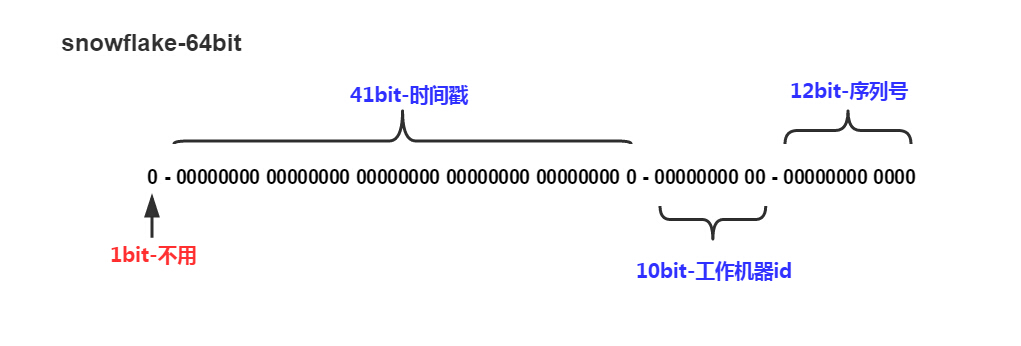
由于该算法依赖于Twitter的一系列基础设施,已经不再维护了。如果要使用的话,可能需要进行一些改造。
MongoDB的ObjectId
和Snowflake算法类似。它设计成轻量型的,不同的机器都能用全局唯一的同种方法方便地生成。
MongoDB从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求,在分布式环境中也很容易应用。
其他参考文章:
What does it take to generate cluster wide unique ID’s in a distributed system